
Scikit-learn – free software tool, designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy.
- Classification – identifying which category an object belongs to
- Regression – predicting a continuous-valued attribute associated with an object
- Clustering – automatic grouping of similar objects into sets.
- Dimensionality reduction – reducing the number of random variables to consider
- Model selection -comparing, validating and choosing parameters and models
- Preprocessing – feature extraction and normalization
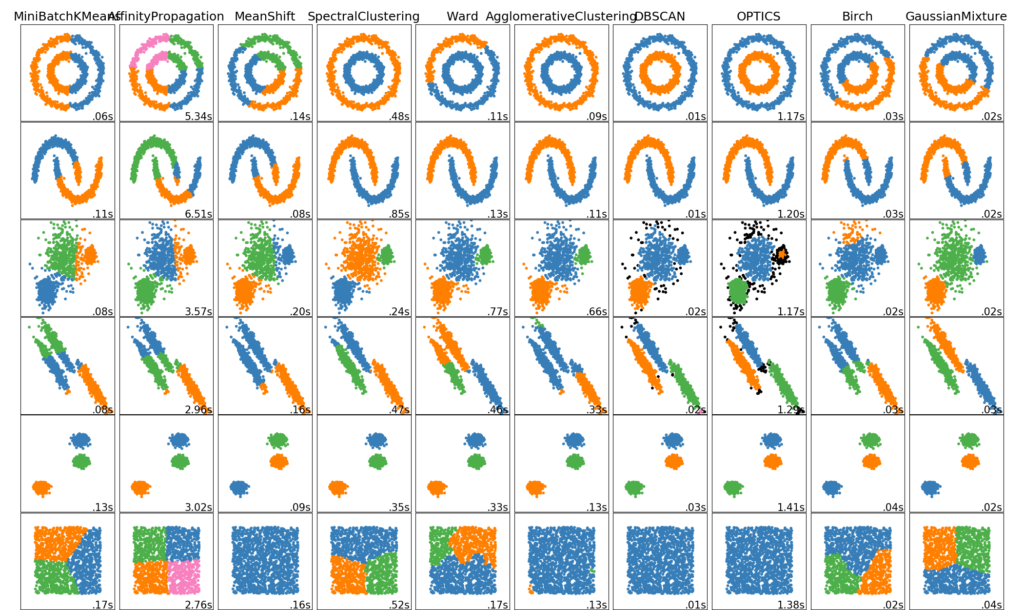
Scikit-learn is largely written in Python, and uses numpy extensively for high-performance linear algebra and array operations. Furthermore, some core algorithms are written in Cython to improve performance. Support vector machines are implemented by a Cython wrapper around LIBSVM; logistic regression and linear support vector machines by a similar wrapper around LIBLINEAR. In such cases, extending these methods with Python may not be possible.
Scikit-learn integrates well with many other Python libraries, such as matplotlib and plotly for plotting, numpy for array vectorization, pandas dataframes, scipy, and many more.