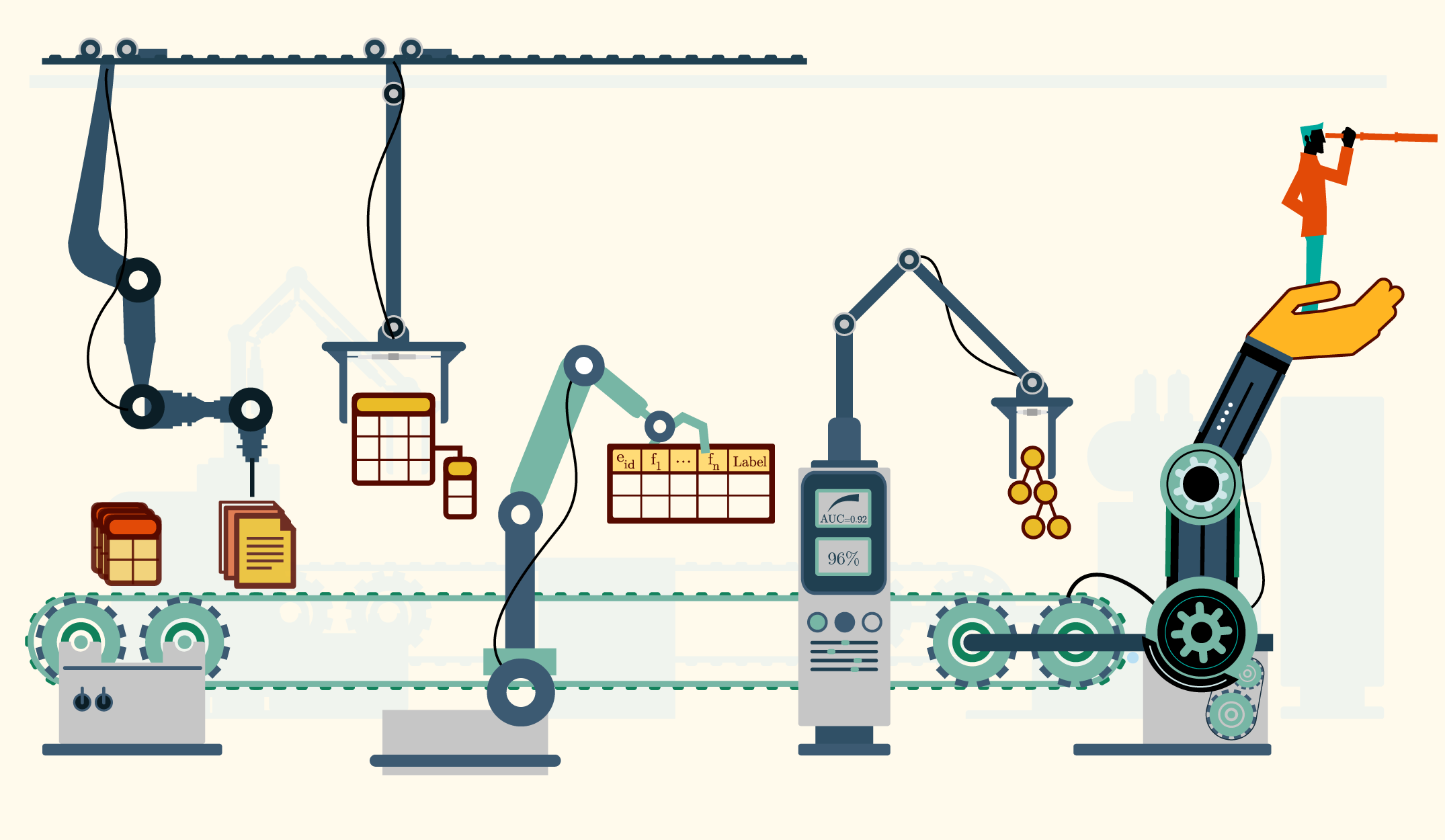
Data Science Machine automation
Data Science Machine is an end-to-end software system that is able to automatically develop predictive models from relational data. The Machine was created at the Computer Science and Artificial Intelligence Laboratory (CSAIL) at MIT. The system automates two of the most human-intensive components of a data science endeavour: feature engineering, and selection and tuning of the machine learning methods that build predictive models from those features.
First, an algorithm called Deep Feature Synthesis automatically engineers features. Most parameters of the system are optimized automatically in pursuit of good general purpose performance. Next, through an approach called Deep Mining, the Machine composes a generalized machine learning pipeline that includes dimensionality reduction methods, feature selection methods, clustering, and classifier design. Finally, it tunes the parameters through a Gaussian Copula Process.
Data Science Machine can accomplish:
(a) posit a data science question
(b) automatically generate features via Deep Feature Synthesis
(c) autotune a machine learning pathway to extract the most out of synthesize Features
Deep Feature Synthesis
Deep Feature Synthesis algorithm uses the concept of primitives in order to generate features for an entity (unique observation in the data) and relationships between entities. The primitives, in essence, are the mathematical functions applied to data such (sum, mean, max, min, average, etc) which return a case-agnostic numerical result and which can be interpreted by a human to mean different things. Different use cases but same mathematical primitive. This has been open sourced under the Featuretools Python library which you can download and experiment with. Featuretools was developed by Feature Labs, a company created by Max Kanter and Kalyan Verramachaneni – the creators of the Data Science Machine.
Defining target value
Target value could be set up and be supplied to the Data Science Machine before the analysis. In other cases, when the target value is not externally provided, Data Science Machine can run the machine learning pipeline for several potential target value and suggest high performing results. To prioritize which ones to pick as target value and show the results to the user, Data Science Machine applies some basic heuristics. At this time, these heuristics are
- Preference for variables that are not derived via feature synthesis algorithm
- Categorical variables with a small number of distinct categories
- Numeric features with high variance
Feature assembly framework
Assembling features for a valid prediction problem is done by Data Science Machine by maintaining a database of metadata associated with each entity-feature. This metadata contains information about the source fields in the original database that were used to form this feature, as well as any time dependencies contained with in it.
Using this metadata, the Data Science Machine assembles a list of all features that were used to calculate the target feature. The Data Science Machine makes this same list for all candidate predicting features. A feature is only usable if these lists contain no overlaps. To handle time dependencies, the Data Science Machine excludes any feature that is assigned an interval number higher than the target feature.
Reusable machine learning pathways
With a target feature and predictors selected, the Data Science Machine implements a parametrized pathway for data preprocessing, feature selection, dimensionality reduction, modeling, and evaluation. To tune the paramters, the Data Science Machine provides a tool for performing intelligent parameter optimization.
Data preprocessing – this includes concertation of null values and categorical values is done , and also feature scaling
Feature selection and dimensionality reduction using Truncated SVD transformation and k-Best methods.
Modeling – system uses random forests to model the relationship between the predictors and the target feature.
Clusterwise modeling – the system uses KMeans classifier random forest methods

Parameter Tuning
Gaussian Copula Process is used (GCP) to model the relationship between parameter choices and the performance of the whole pathway and then used the model to identify better choices. The first step in finding the right parameters is to model a function that captures the relationship between the parameters and the model’s performance. Then sample new parameters and predict what their performance would be using the model’s performance. After that, apply selection strategies to choose what next to sample.
Human-Data Interaction
Interface of Data Science Machine has following features:
Explaining and organizing features – information about all the features at disposal in an accessible manner. Even more, the interface should provide functionalityfor a user to discover the features they want to use through recommendations and filtering
Exposing pathway parameters – possibility for users to manually tweak modelling parameters while still exposing the power of feature optimization in the Data Science Machine.
Experiments with new ideas and application of those results in a positive feedback loop.
Accuracy
The Data Science Machine is able to make predictions that were 94, 96 and 87 percent as accurate as the best submissions in the competitions, and performed better than 615 out of the 906 teams that participated in the competition.
Implementation in MySQL and Python
The Data Science Machine and accompanying Deep Feature Synthesis algorithm are built on top of the MySQL database using the InnoDB engine for tables. All raw datasets are manually converted to a MySQL schema for processing by the Data Science Machine. Logic for calculating, managing, and manipulating the synthesized features is implemented in Python.
Leave a Reply